TL;DR — Jamie Wong의 글로 metaball + Marching Squares를 처음 접한 뒤, 같은 사고를 3D로 확장해서 직접 굴려보고 싶었습니다. 막상 Godot에 옮겨 보니 동적 metaball에서 FPS가 1까지 떨어졌습니다. GPU instancing, spatial culling, dirty region, chunked mesh — 네 가지 최적화를 차례로 적용하며 측정한 결과, 두 가지는 FPS를 크게 끌어올렸고, 나머지 두 가지는 기법 자체는 동작하지만 현재 lab world 규모에서는 의미 있는 FPS 변화로 이어지지 않았습니다. 같은 기법도 규모와 분포에 따라 win이 되기도 lose가 되기도 한다는 점이 가장 큰 교훈이었습니다.
Table of contents
Open Table of contents
들어가며
Jamie Wong의 “Metaballs and Marching Squares”를 읽으며 처음 이 알고리즘을 알게 되었습니다. 인터랙티브한 2D 데모를 따라가며 metaball field와 contour 추출의 흐름을 손으로 그려본 뒤, 자연스럽게 다음 질문이 떠올랐습니다. 같은 사고를 3D로 확장하면 어떤 모습이 될까.
이 글에서 다루는 내용:
- Marching Squares와 Marching Cubes의 개념 정리
- 2D에서 3D로 확장될 때 비용이 어떻게 변하는가
- 동적 metaball rebuild 환경에서의 baseline 측정
- 네 가지 최적화 시도의 측정값과 손익 분석
1. Marching Squares와 Marching Cubes
1.1 Marching Squares (2D)
Marching Squares는 2D scalar field에서 등치선(iso-line)을 추출하는 알고리즘입니다. 흐름은 다음과 같습니다.
- 2D 평면을 일정한 간격의 grid로 sampling합니다. 각 sample point는 scalar 값 하나를 가집니다.
- sample point의 2차원 좌표와 sample point가 가지는 scalar 값은 서로 별개의 존재입니다.
- iso value를 기준으로 각 sample point가 inside( iso)인지 outside( iso)인지 판정합니다.
- cell 하나(인접한 4개 sample point가 만드는 사각형)를 보면 corner 4개의 inside/outside 조합으로 개 case 중 하나에 해당합니다.
- 각 case마다 어떤 edge를 가로지르는 contour line이 그려지는지 미리 정의된 lookup table을 사용합니다.
- edge 위에서 contour가 정확히 어디를 지나가는지는 두 끝점의 scalar 값을 보고 선형 보간(linear interpolation)으로 계산합니다.
Metaball은 이 알고리즘과 잘 어울리는 scalar field 중 하나입니다. 각 ball이 자기 중심에서 거리 제곱에 반비례하는 영향력을 가지고, 여러 ball의 영향이 합산되어 부드러운 등치선을 만들어 냅니다. Jamie Wong의 글을 따라 다음과 같이 정의합니다.
여기서 는 번째 ball의 중심, 는 그 ball의 반지름입니다. 이 정의에서 인 영역이 metaball의 내부가 됩니다(iso value ). 거리 에서 정확히 이 되고, 이면 로 내부 판정이 되는 식입니다. 여러 ball이 가까워지면 각 기여가 합산되어 경계가 자연스럽게 이어집니다.
1.2 Marching Cubes (3D)
Marching Cubes는 정확히 같은 사고를 한 차원 위로 올린 알고리즘입니다.
| 항목 | Marching Squares (2D) | Marching Cubes (3D) |
|---|---|---|
| corner 수 | 4 | 8 |
| case 수 | ||
| 결과 geometry | contour line | triangle mesh |
| lookup table | edge table | edge table + triangle table |
| sample point () | ||
| cell 수 () |
scalar field, iso value, edge interpolation 같은 핵심은 그대로입니다. 달라지는 것은 두 가지입니다.
첫째, case 수가 16에서 256으로 늘어납니다. 8개 corner의 inside/outside 조합이라 이 되고, 각 case마다 어떤 edge들이 surface와 교차하며 그 edge들을 어떻게 묶어 삼각형으로 만들 것인지를 정의한 triTable이 추가적으로 필요합니다.
- Marching Squares 에서는
edgeTable을 통해 ‘top-right’, ‘bottom-left’와 같은 간단한 조합을 이용해 바로 contour line을 그릴 수 있습니다.(e.g. top, right이면 top의 vertices 인터폴레이션 - right vertices 인터폴레이션한 두 정점을 line으로 이어주면 됩니다.) - Marching Cubes 에서는
edgeTable에서 line을 그리는게 아니라 triangle mesh를 그려야 합니다.- 그래서 별도의
triTable을 두어 어떤 순서로 triangle mesh를 그려야 할지 알려주어야 합니다.
- 그래서 별도의
둘째, 차원이 늘면서 sampling과 cell 순회 비용이 세제곱으로 증가합니다. 기준 sample point는 1,024개에서 32,768개로 약 32배 늘어납니다.
2. Baseline: FPS 1, 30K Draw Calls
Grid 32, metaball 3개, dynamic rebuild on 상태로 첫 측정을 했습니다. 화면에는 surface mesh와 함께 grid sampling을 눈으로 확인하기 위한 sample point 시각화가 함께 켜져 있었습니다.
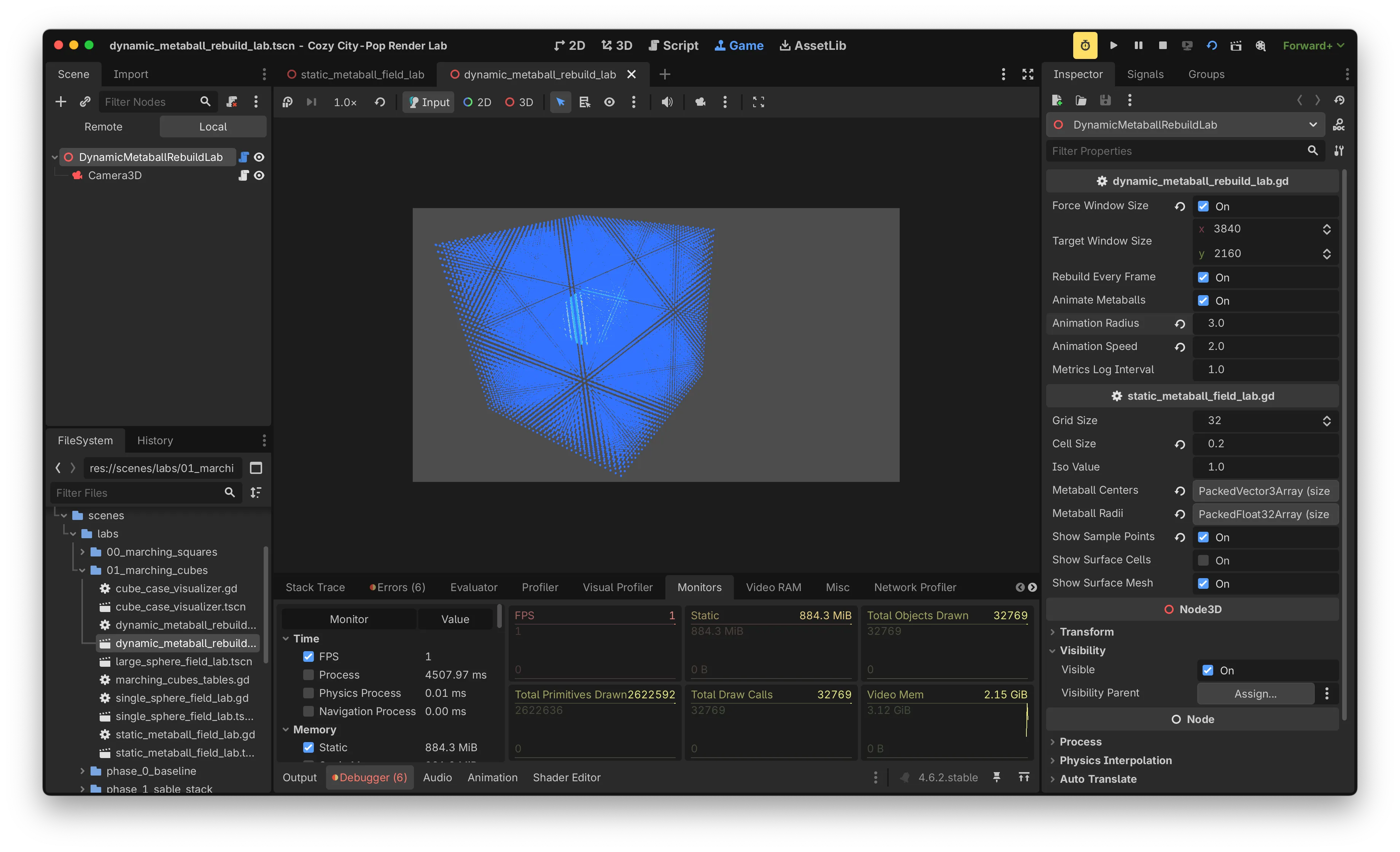
fps: 1
draw calls: 29,678
video memory: 3.12 GiBFrame budget은 60 FPS 기준 ms입니다. FPS 1은 한 프레임에 1,000ms를 쓰고 있다는 의미이고, 목표 대비 60배 부족한 상태였습니다.
가장 먼저 눈에 띄는 수치는 draw calls였습니다. Marching Cubes로 만들어진 surface mesh 자체는 삼각형 수천 개 수준일 텐데, draw call이 약 3만 개에 달했습니다. 이것은 알고리즘 자체의 비용이 아니라 sample point 시각화의 구현 방식에서 온 비용이었습니다.
# sample point 시각화 (문제 지점)
for x in range(grid_size):
for y in range(grid_size):
for z in range(grid_size):
var instance := MeshInstance3D.new()
instance.mesh = SphereMesh.new()
_root.add_child(instance)개의 sample point 각각이 별도 노드로 scene tree에 등록되고, 매 프레임 별도의 draw call로 처리되고 있었습니다. sample point는 알고리즘을 이해하기 위한 시각화 오브젝트이지만, 시각화 자체의 비용이 알고리즘보다 비싼 상황이었습니다.
3. 사고의 두 축: 단가와 일량
본격적인 최적화에 들어가기 전에, 이후 시도들을 분류할 한 가지 사고 프레임을 정리합니다.
이 글의 모든 최적화는 두 축으로 나뉩니다.
단가(per-unit cost) 줄이기 — cell 하나를 처리하는 비용을 깎습니다.
ImmediateMesh→ArrayMesh- nested
Array→PackedFloat32Array - GDScript → C++ / GDExtension
- CPU → GPU compute
일량(work amount) 줄이기 — 처리할 cell 수 자체를 줄입니다.
- per-ball AABB culling
- dirty region update
- chunked grid + per-chunk dirty flag
두 축은 서로 곱셈으로 합산됩니다. 같은 작업이라도 어느 축에서 줄이는지에 따라 손익 구조가 달라집니다. 이번 글의 시도들을 미리 분류하면 다음과 같습니다.
| 시도 | 축 | 결과 |
|---|---|---|
| MultiMeshInstance3D | 단가 (draw call) | 큰 win |
| Spatial culling (cell) | 일량 | win |
| Dirty region (field) | 일량 | win |
| Chunked mesh rebuild | 일량 | 현 규모에서 비효율 |
4. 네 가지 최적화 시도
4.1 GPU Instancing / Batching
가장 먼저 손볼 곳은 draw call이었습니다. MeshInstance3D를 sample point마다 하나씩 만드는 구조에서, 같은 sphere mesh를 transform만 바꿔 반복 렌더링하는 구조로 전환했습니다. Godot에서는 MultiMeshInstance3D가 이 역할을 합니다.
# 변경: inside/outside 그룹별로 MultiMeshInstance3D 하나씩
var multimesh := MultiMesh.new()
multimesh.transform_format = MultiMesh.TRANSFORM_3D
multimesh.mesh = SphereMesh.new()
multimesh.instance_count = inside_count
for i in inside_count:
multimesh.set_instance_transform(i, transforms[i])MultiMeshInstance3D는 같은 mesh를 여러 transform으로 반복해서 그리는 작업에 특화된 노드입니다. Scene tree에 추가되는 노드는 그룹당 하나뿐이고, GPU instancing을 통해 단일 draw call로 수만 개의 sphere를 렌더링합니다.
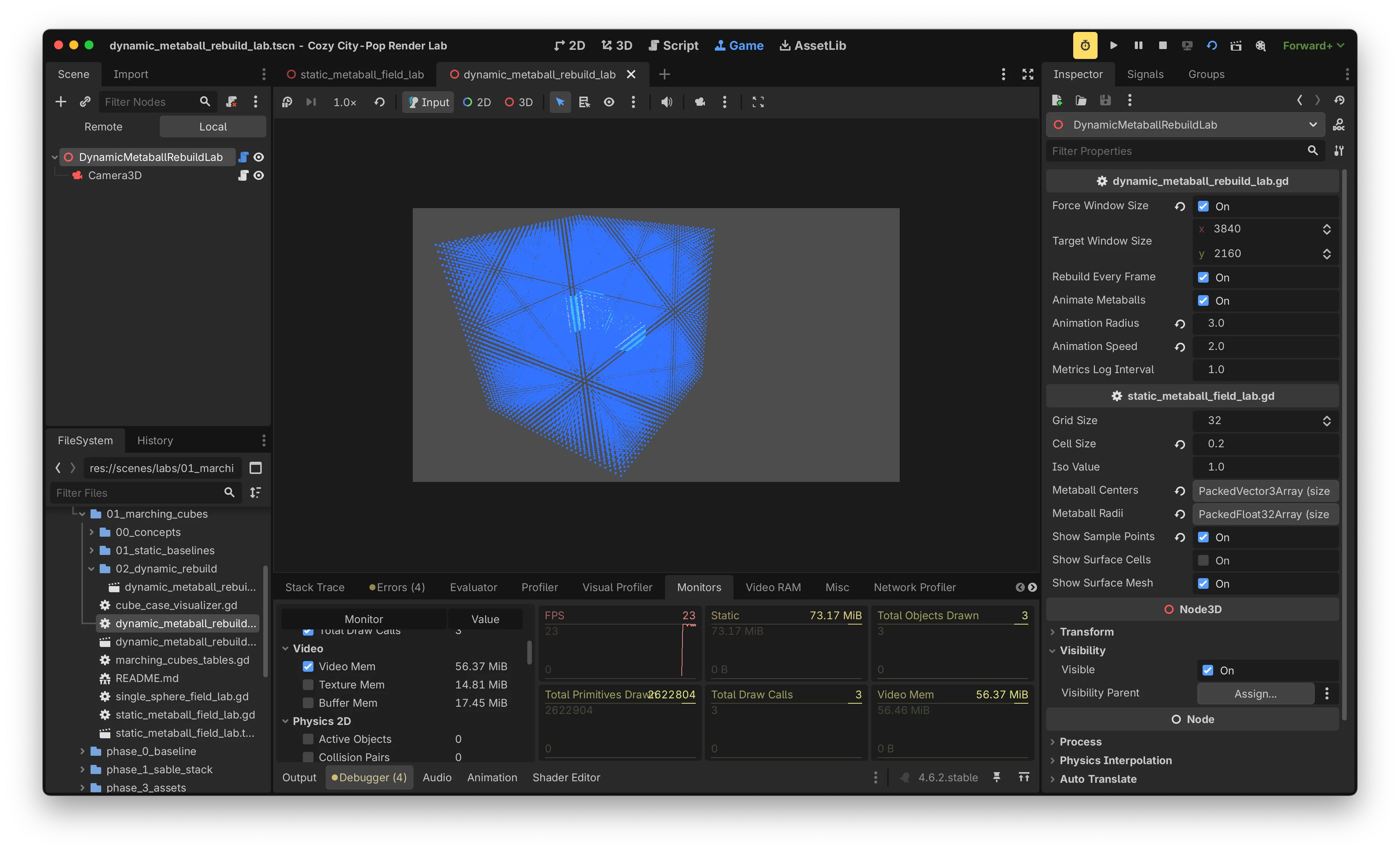
fps: 23
draw calls: 3
video memory: 56.37 MiB
static memory: 73.17 MiBDraw call이 29,678에서 3으로, video memory가 3.12 GiB에서 56 MiB로 줄었습니다. 3개의 draw call은 inside 그룹, outside 그룹, surface mesh입니다. Marching Cubes가 만들어내는 surface mesh 자체는 draw call 측면에서 이미 효율적이라는 점도 같이 확인되었습니다.
다만 FPS 23은 frame budget(16.6ms) 안에 들어오지 못한 상태입니다. Draw call 병목은 해결됐지만 CPU rebuild 비용이 남았습니다.
fps: 23.0 | field ms: 10.5 | mesh ms: 33.26 | total ms: 43.75
surface cells: 704 | triangles: 1,392total ms: 43.75를 역산하면 로, 측정된 FPS와 거의 일치합니다. 이후의 시도는 모두 CPU rebuild 시간을 깎는 방향입니다.
- 현재 Marching Cubes의 알고리즘은 전부 CPU에서 처리하며, 셰이더로 이식은 이번 실험에서는 논외입니다.
4.2 Spatial Culling
다음 관찰은 단순합니다. 전체 cell 수는 29,791개이지만, surface가 실제로 지나가는 cell은 704개에 불과합니다. 전체의 약 2.3% 입니다.
CPU는 매 프레임 다음 작업을 모든 cell에 대해 수행합니다.
- 모든 sample point의 field 값 계산
- 모든 cell을 순회
- 각 cell의 8개 corner 값을 보고 cube index 계산
- cube index가 0 또는 255면 skip
- 그 외면 triangle 생성
대부분의 cell이 4단계에서 skip되지만, 그 직전까지의 corner value 접근과 cube index 계산은 이미 수행된 상태입니다. 이 비용 자체를 줄이기 위해, 각 metaball의 영향권에서 일정 배수만큼의 AABB를 만들어 그 안의 cell만 candidate로 등록하는 방식으로 일량을 줄였습니다.
multiplier는 metaball radius에 곱해 candidate AABB를 결정하는 안전 margin입니다.
| multiplier | candidate cells | mesh ms | total ms | fps |
|---|---|---|---|---|
| off | 29,791 | ~33 | ~43 | ~23 |
| 3.0 | 14,600 ~ 17,000 | ~30 | ~40 | 24 ~ 25 |
| 2.0 | 5,500 ~ 7,500 | ~20 | ~30 | 31 ~ 33 |
| 1.0 | 1,200 ~ 1,800 | ~15 | ~24 | 39 ~ 40 |
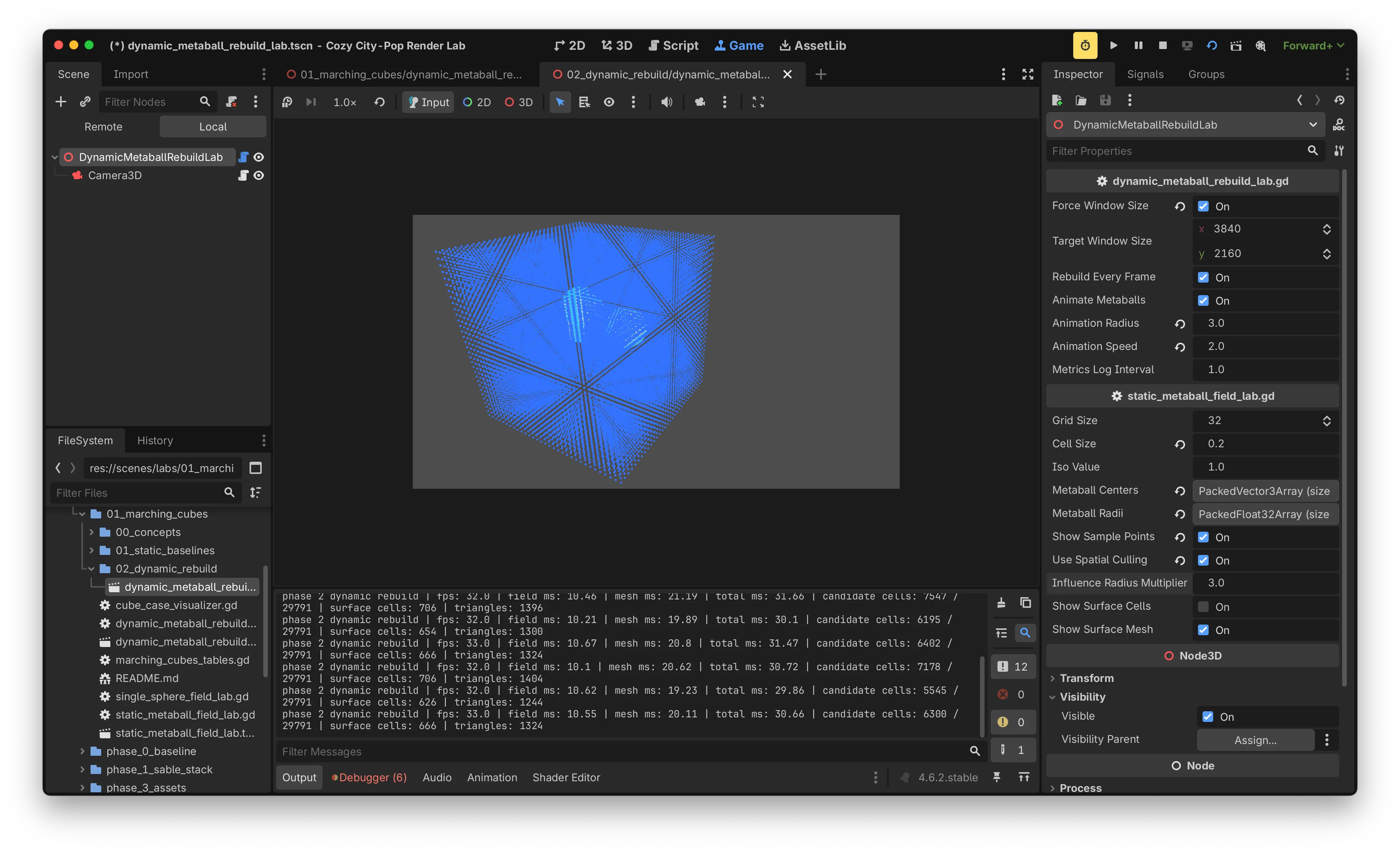
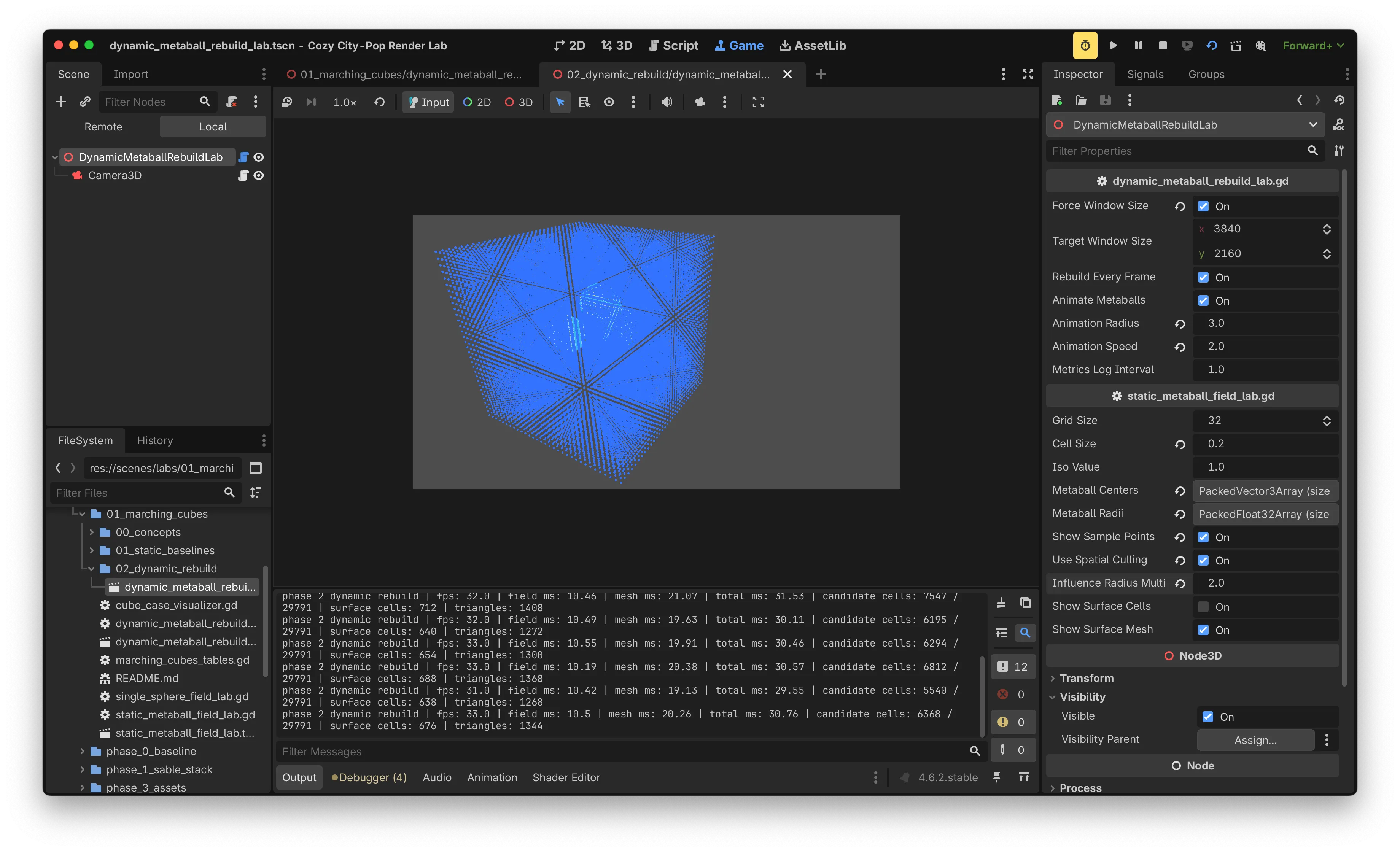
multiplier 1.0에서는 surface가 잘려 보이는 clipping이 관찰되었습니다. 안전 margin과 성능의 trade-off는 시각적으로 검증하면서 결정해야 하는 영역입니다. 실험 환경에서는 multiplier 2.0을 baseline으로 채택했습니다.
이후 시도들에 대한 사전 안내 — 4.3과 4.4는 dirty region과 chunked mesh rebuild를 다룹니다. 두 기법 모두 개념적으로는 일량을 더 좁히는 자연스러운 다음 단계이지만, 현재 lab world 규모(grid 32, metaball 3)에서는 FPS를 크게 끌어올리지 못했습니다. dirty region은 측정 가능한 미세 절감을 보였고, chunked mesh rebuild는 손익이 맞지 않았습니다. 두 시도 모두 “이 규모에서는 작은 변화”라는 점을 미리 짚고, 무엇을 얻고 무엇을 못 얻었는지를 정리합니다.
4.3 Dirty Region (Field)
Spatial culling이 “이번 프레임에 다룰 cell”을 줄였다면, dirty region은 “이번 프레임에 값이 바뀐 cell”만 다루는 한 단계 더 좁은 일량 정의입니다.
Metaball이 매 프레임 움직이기 때문에, 이전 프레임 영향권과 현재 프레임 영향권의 합집합 안의 sample만 dirty가 됩니다. 그 외 sample은 이전 프레임 값을 그대로 재사용합니다.
이전 프레임 candidate ∪ 현재 프레임 candidate = dirty region첫 프레임에는 모든 sample을 계산하지만, 이후 프레임부터는 dirty sample만 갱신합니다. 다만 scalar field가 metaball 가중치의 합이라 dirty 영역 안에서는 합을 다시 만드는 방식으로 처리합니다.
같은 씬(grid 32, metaball 3, spatial culling on) 기준 dirty region을 켜고 끈 측정값을 비교했습니다.
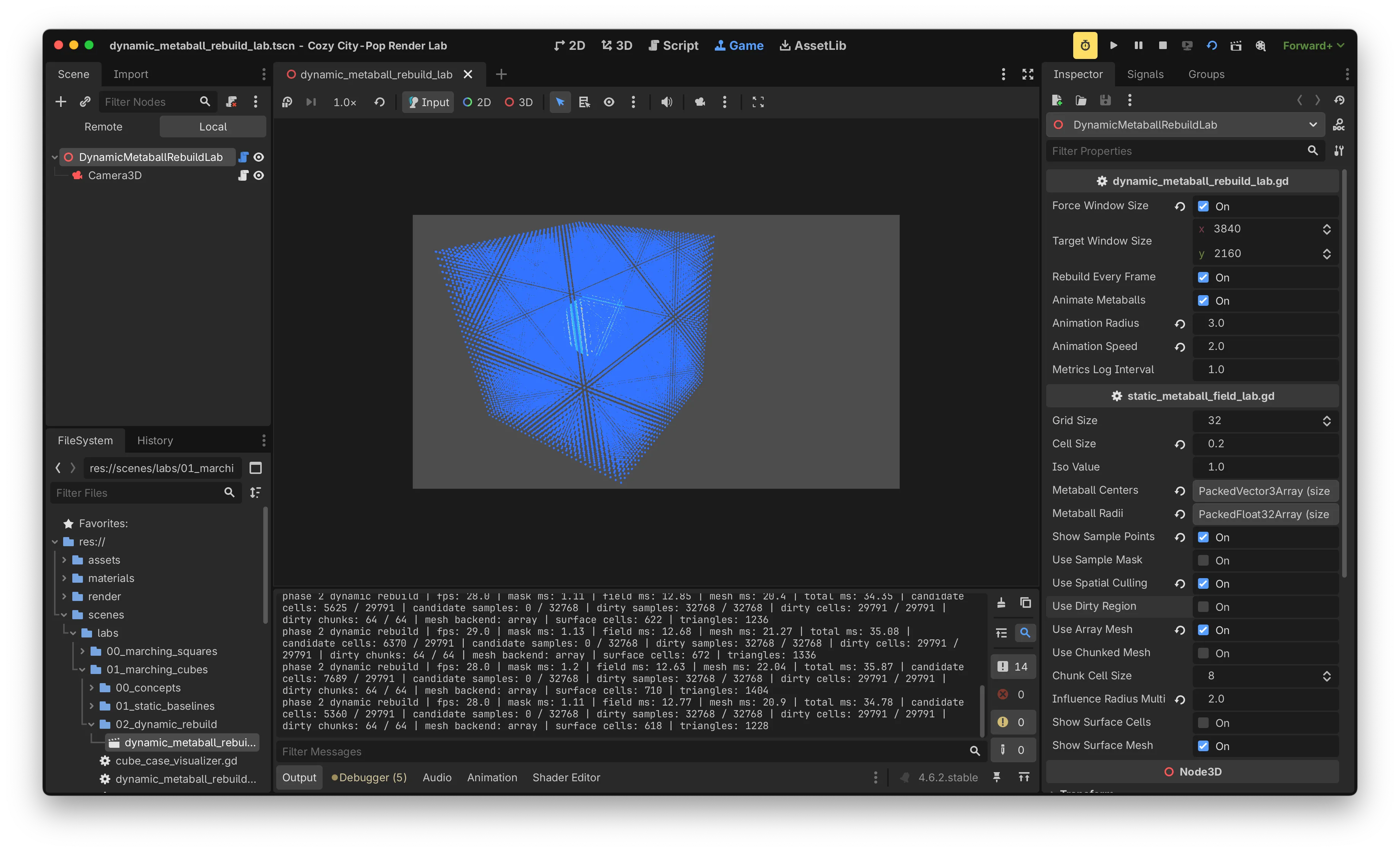
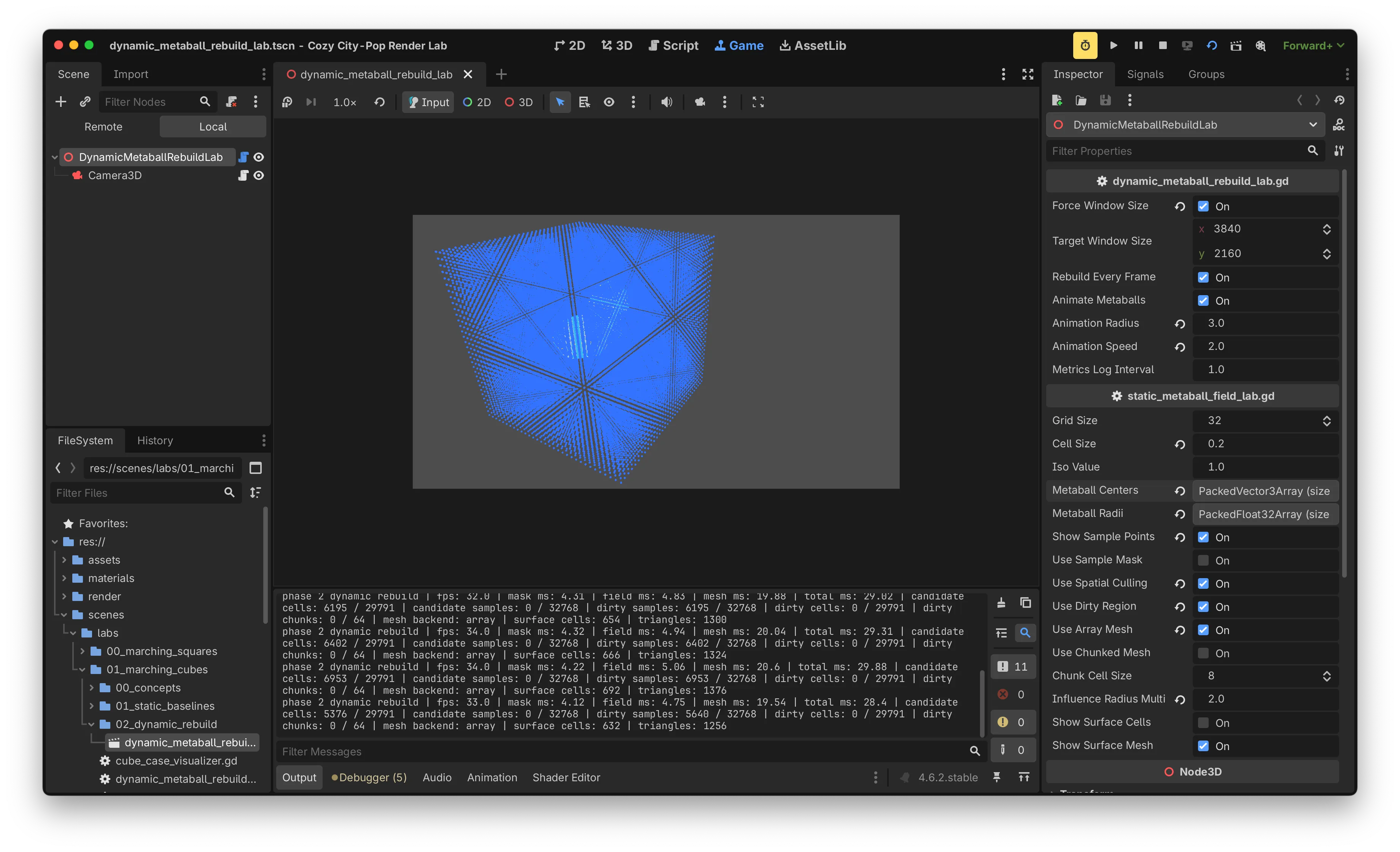
| 항목 | off | on | Δ |
|---|---|---|---|
| field ms | ~12.6 | ~5.2 | −7.4 |
| mask ms | ~1.1 | ~4.6 | +3.5 |
| mesh ms | ~20.5 | ~20.0 | ~0 |
| total ms | ~35 | ~29 | −6.0 |
| fps | 28 ~ 29 | 30 ~ 32 | +2 ~ 4 |
표를 부분별로 보면 dirty region 적용 자체는 의도한 효과를 보였습니다. field ms는 12.6에서 5.2로 약 60% 줄었고, 이는 dirty 영역 안의 sample만 갱신한 결과입니다. 손익분기 식으로 정리하면 다음과 같습니다.
이 식 자체는 양수(ms)이고, 표에 잡힌 total ms 차이는 약 −6.0ms입니다(항목별 합과 total의 차이는 표에 없는 보조 비용과 측정 분산에서 오는 것으로 추정합니다).
다만 현재 lab world 규모에서 전체 frame time 단축으로 이어지는 효과는 작았습니다. (4.2를 적용한 fps 31-33 수준에서 dirty region을 적용했을 때 30-32 수준으로 효과가 미미)
- mesh ms(~20)가 여전히 frame budget의 가장 큰 비중을 차지함
- dirty region은 그중 field 영역만 줄이는 기법
- 줄어든 field 비용 자체도 grid 32 / metaball 3 규모에서는 절대값이 크지 않음
즉 dirty region은 기법으로서는 의도대로 동작하지만, 우리 월드 규모에서는 FPS 단위의 의미 있는 win으로 환산되지 않았다는 결론입니다. metaball 수가 더 많거나 grid가 더 커서 field ms가 frame budget의 절반 이상을 차지하는 환경이라면 같은 기법이 훨씬 큰 효과를 낼 것입니다.
4.4 Chunked Mesh Rebuild
Dirty region을 field에 적용하고 나면 자연스러운 다음 질문이 나옵니다. mesh 빌드도 dirty 영역만 다시 만들 수 없을까.
문제는 mesh가 하나의 surface로 통째로 만들어진다는 점입니다. 일부 삼각형만 갈아끼우는 것이 어렵기 때문에, grid를 여러 chunk로 나누고 각 chunk가 자기 mesh를 가지게 한 뒤, dirty region과 겹치는 chunk만 다시 빌드하는 구조로 변경했습니다.
grid_size = 32 기준 cell은 각 축마다 31개입니다. chunk_cell_size = 8이라면 x축으로 4개의 chunk(8, 8, 8, 7 cells)가 나오고, y/z축으로 확장하면 개의 chunk가 만들어집니다.
Sample point 하나가 갱신되면 그 point를 corner로 가지는 인접 cell 8개가 dirty가 되고, 이 cell들이 속한 chunk가 rebuild 대상에 포함됩니다.
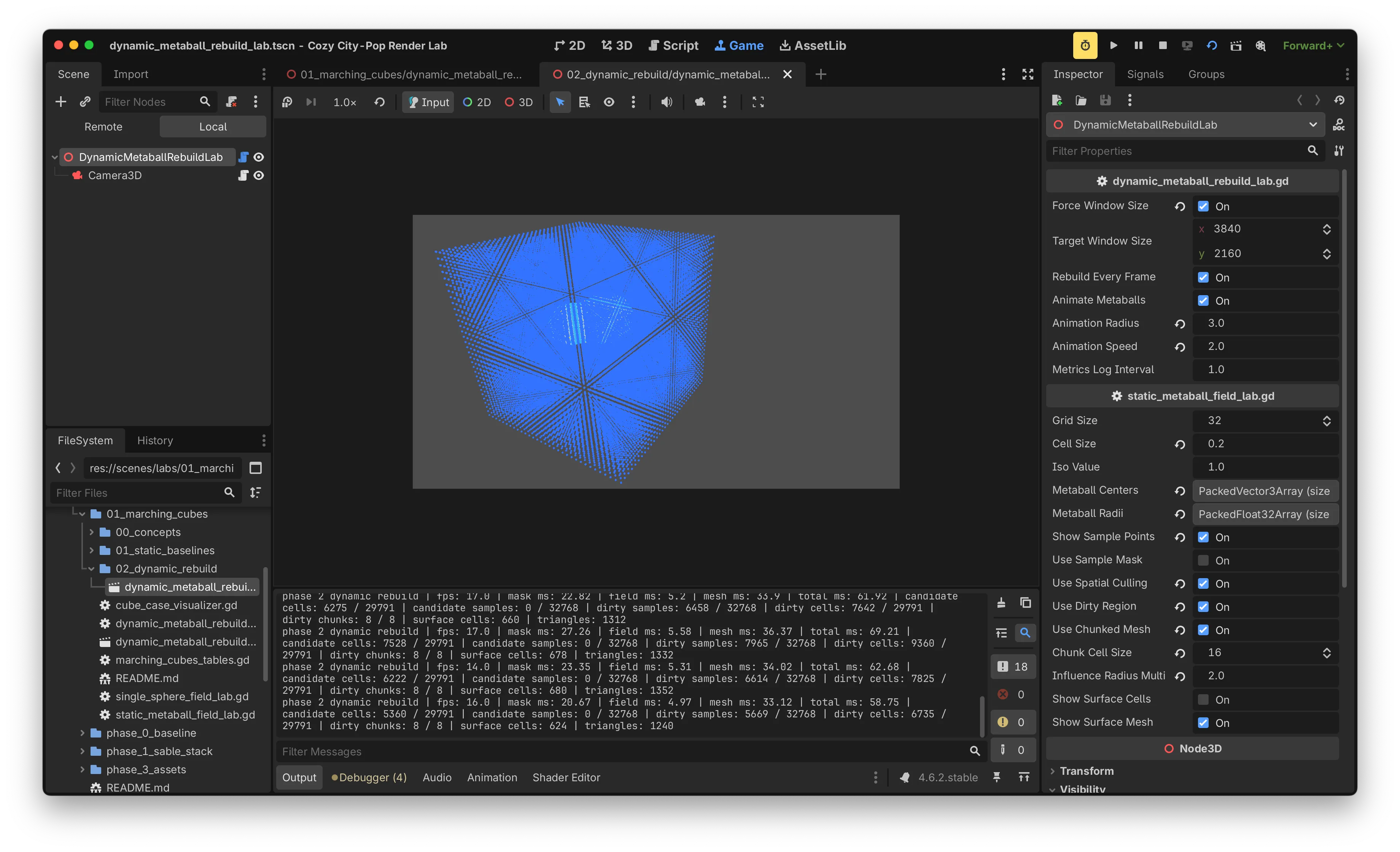
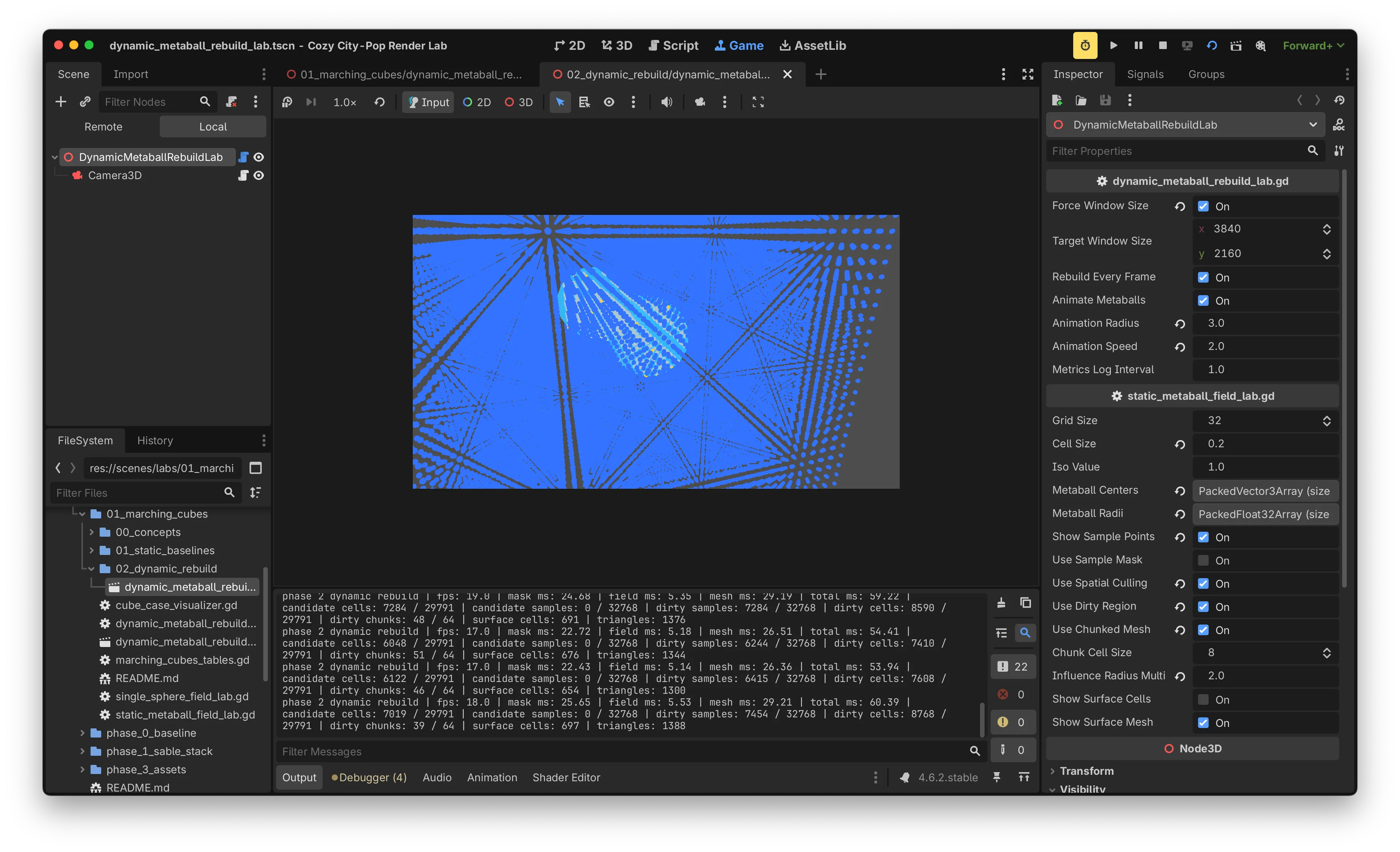
chunk_cell_size = 16 → 전체 8개 chunk가 거의 항상 dirty
chunk_cell_size = 8 → 전체 64개 chunk 중 39 ~ 51개가 dirty결과적으로 chunk 분할 비용이 절약량보다 커서 FPS와 mesh ms 모두 악화되었습니다. 핵심 병목인 CPU rebuild 시간을 줄이지 못했습니다.
작은 lab world에서는 metaball 3개의 영향권이 grid 전체에서 차지하는 비율이 높습니다. 그래서 어떻게 나눠도 대부분의 chunk가 dirty 상태로 기록됩니다.
grid의 사이즈가 훨씬 큰 환경에서는 chunking 을 하여 dirty 상태가 된 부분만 mesh를 다시 만드는 것이 효과가 좋을 것이라는 예상은 해볼 수 있습니다만, 현재 환경에서는 오버헤드가 더 큰 것으로 볼 수 있겠습니다.
정리하며
네 가지 시도의 손익을 한 줄로 요약합니다.
| 시도 | 축 | 결과 | 한 줄 교훈 |
|---|---|---|---|
| MultiMeshInstance3D | 단가 | FPS 1 → 23 | 시각화 자체의 비용이 알고리즘보다 비쌀 수 있다 |
| Spatial culling | 일량 | FPS 23 → 31 | surface 근처만 다루면 일량이 1/5로 줄어든다 |
| Dirty region (field) | 일량 | field −7.4ms / FPS +2~4 | 기법은 동작하지만 현 규모에서는 전체 FPS 영향이 작다 |
| Chunked mesh rebuild | 일량 | 비효율 | 규모가 더 클 때 효과적일 듯 |
핵심 요약:
- 차원이 하나 늘면 늘어나는 비용은 어마어마(32배…)하다.
- 전체 작업의 총량을 줄이는 것이 가장 효과적이다.
- 프로젝트 규모마다 적용해야 하는 최적화가 달라질 수 있다. 좋다고 다 적용하면 안좋아진다.
참고 자료
- Jamie Wong — Metaballs and Marching Squares — 이 글의 출발점이 된 인터랙티브 2D 튜토리얼
- Paul Bourke — Polygonising a Scalar Field — Marching Cubes 원전. cube index, edge 번호, triangle table의 표준 레퍼런스
- Godot 4.6 — Using ArrayMesh — procedural mesh 생성 공식 문서
- Godot 4.6 — MultiMesh — GPU instancing 공식 문서
이 게시물은 학습한 내용을 바탕으로 초안을 작성한 뒤, LLM의 도움을 받아 내용을 검수하고 다듬어 완성되었습니다.