TL;DR — 가우시안 블러는 함수를 커널로 사용하며, separable 특성 덕분에 2D 연산을 1D 두 번으로 분리하여 GPU에서 효율적으로 처리할 수 있습니다. Vulkan compute shader로 구현한 뒤, 클릭한 픽셀의 GPU 결과를 CPU 계산으로 재현하여 정확성을 검증했습니다.
Table of contents
Open Table of contents
들어가며
이미지 블러는 그래픽스의 기본 연산입니다. 블룸(빛번짐), DOF(피사계 심도), UI 배경 흐림 등 후처리 효과의 기반이 되고, 블러 자체가 이미지 처리의 핵심 도구이기도 합니다.
그중 가우시안 블러는 가장 널리 쓰이는 블러 방식입니다. 단순 평균(박스 블러)보다 원본을 잘 보존하면서 부드럽게 흐리고, separable 특성 덕분에 GPU에서 효율적으로 실행할 수 있습니다.
이 글에서는 가우시안 함수의 수식을 분해하고, separable convolution이 왜 가능한지 증명한 뒤, Vulkan compute shader로 구현하고, GPU 결과를 수학으로 검증하는 과정을 다룹니다. 수식이 등장하지만, 코드와 1:1로 대응시키며 설명하므로 수학 배경 없이도 따라갈 수 있습니다.
이 글에서 다루는 내용:
- 가우시안 함수의 모양과 가 블러 강도를 결정하는 이유
- separable convolution으로 2D 블러를 1D 두 번으로 바꾸는 원리
- Vulkan
compute shader로 가로/세로 블러를 구현하고 결과를 검증한 과정
사전 지식: Vulkan의 기본적인
compute shader,dispatch, 이미지 읽기/쓰기 개념을 전제로 합니다.
1. 컨볼루션 — 커널이 이미지 위를 슬라이딩하는 연산
이미지 블러의 핵심은 컨볼루션(Convolution) 입니다. 커널(Kernel)이라는 작은 숫자 행렬을 이미지 위에 슬라이딩하면서, 각 픽셀의 새 값을 계산하는 연산입니다.
- 커널의 각 값 × 대응하는 픽셀 값을 전부 더하면 해당 픽셀의 새 값이 됩니다
- 이 과정을 모든 픽셀에 대해 반복합니다
- 커널의 종류에 따라 결과가 달라집니다: 박스 커널(단순 평균), 가우시안 커널(가중 평균), 엣지 검출 등
박스 블러 vs 가우시안 블러
- 박스 블러: 이웃 픽셀을 전부 더하고 평균을 냅니다. 모든 픽셀이 동일한 가중치를 가집니다.
- 가우시안 블러: 중심 픽셀의 가중치가 가장 높고, 멀수록 가중치가 줄어듭니다. 원본이 더 잘 보존됩니다.
2. 가우시안 함수 — 수식을 코드로
수식
중심에서 멀어질수록 값이 부드럽게 감소하는 함수입니다. 좌우 대칭이라 블러에 적합합니다.
수식 분해
밑: (자연상수, ≈ 2.718)
부드러운 감쇠 곡선을 만드는 수학 상수입니다. 코드에서는 exp() 함수가 를 계산합니다.
지수:
- : 커널 중심 픽셀(0)에서 몇 칸 떨어졌는지를 나타냅니다
- 이므로 방향과 무관합니다. 가우시안이 좌우 대칭인 이유입니다
- : 종 모양의 폭을 결정합니다
- 가 크면 분모가 커지고, 지수의 절대값이 작아져 감쇠가 느려집니다. 블러가 강해집니다
- 가 작으면 감쇠가 빠르고 중심 픽셀 위주가 되어 블러가 약해집니다
- (음수 부호): 지수가 항상 이 되어 결과가 항상 0~1 사이입니다
과 인 이유:
- : 방향을 없애기 위해 부호를 제거합니다. 좌우 대칭을 만드는 장치입니다
- : 와 단위를 맞추기 위한 것입니다. 는 “시그마 몇 개분 떨어졌는가”라는 무차원 비율이 됩니다
에 따른 가중치 변화
일 때, 중심에서 3칸만 벗어나도 가중치가 0.011까지 떨어집니다. 일 때, 3칸 벗어나도 가중치가 0.607로 여전히 높습니다.
가 크면 같은 거리에서도 가중치가 높게 유지되어, 멀리 있는 픽셀도 많이 반영됩니다.
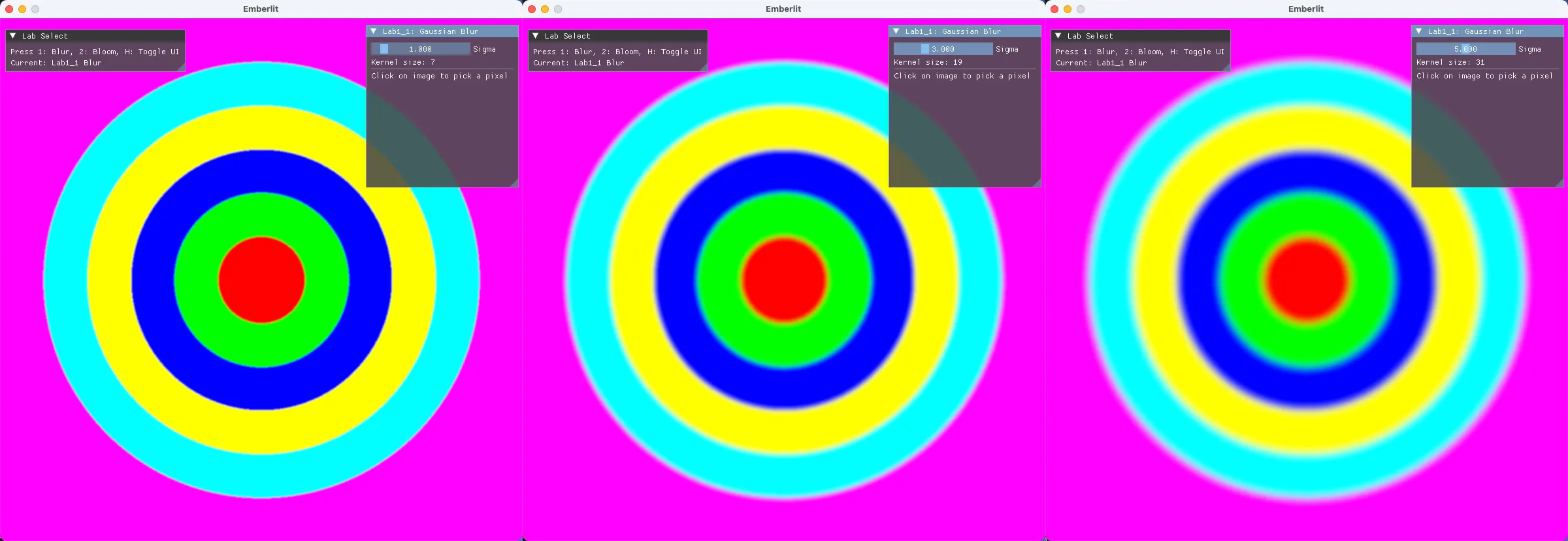
커널 크기와 의 관계
- 경험적 공식: 커널 크기
- 보통 중심 기준 범위를 잡으면 연속 가우시안의 대부분을 담을 수 있습니다
- 가 큰데 커널이 작으면 가우시안 꼬리(tail)가 잘린 truncated Gaussian 이 됩니다
- 박스 블러가 되는 것은 아니지만, 의도한 분포를 충분히 담지 못해 블러 품질이 나빠질 수 있습니다
커널 생성 + 정규화
- 를 결정합니다
- 커널 크기를 결정합니다 ()
- 각 위치 에 대해 를 계산합니다
- 전체 합이 1이 되도록 정규화합니다 — 밝기를 보존하기 위해서입니다. 합이 1보다 크면 밝아지고, 1보다 작으면 어두워집니다. 블러는 색을 섞는 연산이지 밝기를 바꾸는 연산이 아닙니다
σ=1, 커널 크기 7:
G(x): 0.011 0.135 0.607 1.000 0.607 0.135 0.011 (합 = 2.506)
정규화: 0.004 0.054 0.242 0.399 0.242 0.054 0.004 (합 = 1.000)코드로는 한 줄입니다:
float weight = exp(-(x * x) / (2.0f * sigma * sigma));3. Separable Convolution — 을 으로
왜 빠른가
커널의 2D 컨볼루션은 픽셀당 번 연산이 필요합니다. Separable 방식은 1D를 가로 한 번 + 세로 한 번, 픽셀당 번 연산으로 줄입니다.
이면 49 vs 14. 3.5배 빠릅니다.
어떤 커널이 separable한가
2D 커널이 두 1D 벡터의 외적(Outer Product) 으로 분해 가능할 때만 separable합니다.
- 외적(Outer Product)은 벡터 외적(Cross Product)과 다릅니다
- Outer Product는 1D 벡터 두 개로 2D 행렬을 만드는 연산입니다
[v₁]
v ⊗ h = [v₂] × [h₁, h₂, h₃]
[v₃]
= [v₁h₁ v₁h₂ v₁h₃]
[v₂h₁ v₂h₂ v₂h₃]
[v₃h₁ v₃h₂ v₃h₃]가우시안 함수는 로 분리되므로 separable합니다. 모든 커널이 이렇게 분리 가능한 것은 아닙니다 (예: 일부 edge detection 커널은 불가능합니다).
핵심: 가로 전체를 먼저, 세로 전체를 나중에
두 패스는 절대 섞이지 않습니다.
- 가로 패스: 모든 픽셀 에 가로 1D 커널을 적용하여 중간 이미지를 생성합니다
- 세로 패스: 중간 이미지 에 세로 1D 커널을 적용하여 최종 이미지를 생성합니다
처음에는 “한 픽셀씩 가로 → 세로 순차로 하는 것”이라고 오해하기 쉽습니다. 가로 패스가 전체에 먼저 적용되어야 세로 패스에서 올바른 중간 결과를 읽을 수 있습니다.
원본과 결과 이미지를 분리해야 하는 이유:
- 같은 이미지에서 읽으면서 동시에 쓰면, 이미 수정된 값을 다른 픽셀이 읽을 수 있습니다 (in-place 오염)
- CPU에서도 GPU에서도 동일한 문제입니다. 입력(
readonly)과 출력(writeonly) 이미지를 분리해야 합니다
수식 증명: 2D = 1D + 1D
이미지 픽셀 (중심 e 주변 3×3):
a b c
d e f
g h i2D 컨볼루션 (한 번에):
e' = v₁h₁·a + v₁h₂·b + v₁h₃·c
+ v₂h₁·d + v₂h₂·e + v₂h₃·f
+ v₃h₁·g + v₃h₂·h + v₃h₃·iSeparable (가로 → 세로):
가로 패스:
A = h₁a + h₂b + h₃c
B = h₁d + h₂e + h₃f
C = h₁g + h₂h + h₃i
세로 패스:
e' = v₁·A + v₂·B + v₃·C
= v₁h₁·a + v₁h₂·b + ... + v₃h₃·i분배법칙으로 전개하면 2D 결과와 항이 하나하나 동일합니다.
4. GPU 구현 — Vulkan Compute Shader
CPU 블러를 건너뛴 이유
로드맵에는 “CPU 가우시안 블러 → GPU compute shader” 순서가 있었습니다. CPU 구현을 건너뛰고 바로 GPU로 간 이유는 다음과 같습니다:
- 가우시안 함수와 separable 개념은 수학 단계에서 이미 이해를 마쳤습니다
- CPU
for문과 GPU 셰이더의 블러 로직은 본질적으로 같습니다 (가중 합산) - 시간을 GPU 파이프라인 이해에 집중하는 편이 더 가치 있다고 판단했습니다
- 디버깅이 어려울 수 있지만, 피킹 검증으로 보완할 수 있습니다
왜 Compute Shader인가
가우시안 블러는 모든 픽셀에 대해 동일한 연산을 반복하는 작업입니다. GPU의 수만 개 스레드가 각 픽셀을 동시에 처리합니다. graphics pipeline의 버텍스/래스터화 과정이 필요 없는 순수 연산이라 compute shader가 적합합니다.
CPU: for문으로 640,000번 순차 실행
GPU: 640,000 스레드가 한꺼번에 병렬 실행dispatch 2번이 필수인 이유
GPU의 workgroup 간에는 동기화가 불가능합니다. 셰이더 내부에서 “가로가 끝나면 세로 시작”을 할 수 없습니다.
dispatch 1 (가로): 모든 픽셀 가로 블러 → 중간 이미지
배리어: 가로 쓰기 완료 보장
dispatch 2 (세로): 모든 픽셀 세로 블러 → 최종 이미지각 스레드는 자기 좌표의 픽셀만 처리합니다. 입력 이미지에서 읽고(readonly), 출력 이미지에 씁니다(writeonly). 병렬 스레드 간 오염이 구조적으로 불가능합니다.
셰이더 코드 — 1개로 가로/세로 모두 처리
처음에는 가로 셰이더, 세로 셰이더를 따로 만들려 했습니다. 하지만 push_constant로 방향만 전환하면 셰이더 1개, 파이프라인 1개로 충분합니다:
layout(push_constant) uniform Params {
float sigma;
int radius;
int direction; // 0: 가로, 1: 세로
};
void main() {
ivec2 pos = ivec2(gl_GlobalInvocationID.xy);
ivec2 size = imageSize(inputImage);
if (pos.x >= size.x || pos.y >= size.y) return;
float total_weight = 0.0;
vec4 total_color = vec4(0.0);
for (int i = -radius; i <= radius; ++i) {
ivec2 offset = (direction == 0) ? ivec2(i, 0) : ivec2(0, i);
ivec2 coord = clamp(pos + offset, ivec2(0), size - 1);
float weight = exp(-(i * i) / (2.0 * sigma * sigma));
total_weight += weight;
total_color += weight * imageLoad(inputImage, coord);
}
imageStore(outputImage, pos, total_color / total_weight);
}핵심 포인트:
direction이 0이면offset이(i, 0)— 가로 방향으로만 이동합니다direction이 1이면offset이(0, i)— 세로 방향으로만 이동합니다clamp로 이미지 경계를 넘지 않도록 처리합니다total_weight로 나누어 정규화합니다. 커널을 미리 정규화하는 대신, 실시간으로 가중치 합을 구하여 나누는 방식입니다
5. 검증 — GPU 결과를 수학으로 확인
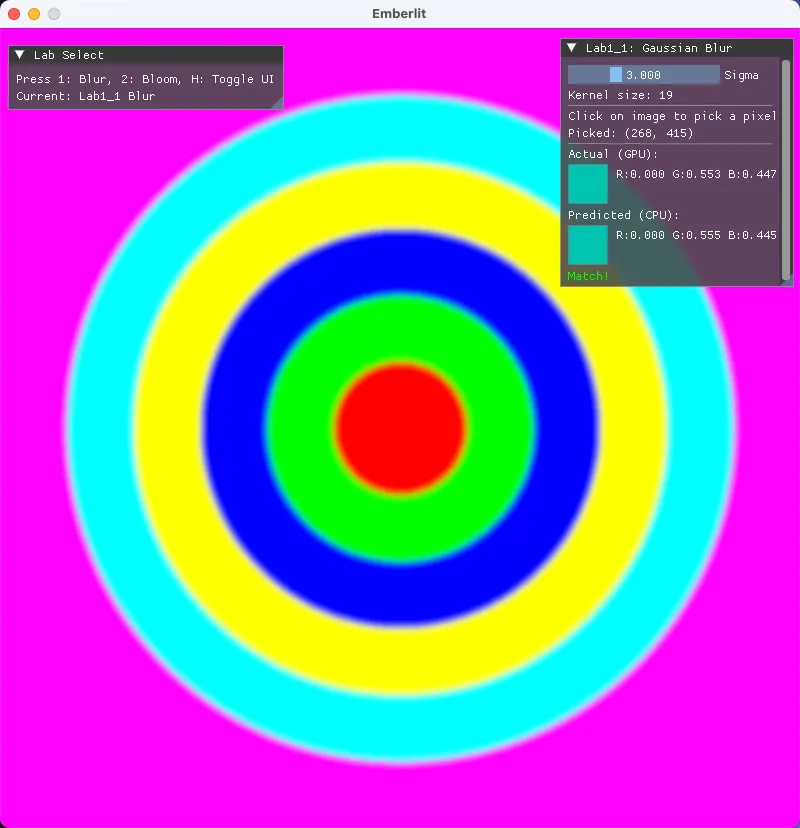
셰이더가 올바르게 동작하는지 확인하기 위해, 클릭한 픽셀의 블러 결과를 CPU에서 동일한 가우시안 계산으로 재현하여 비교했습니다.
검증 흐름:
1. 동심원 이미지에서 블러 적용
2. 마우스로 경계 부근 클릭
3. GPU 결과 (staging buffer로 readback)
4. CPU 예측값 (원본 픽셀 + 가우시안 가중치로 separable 계산)
5. 두 값 비교 → 일치하면 셰이더 구현이 정확CPU 예측 계산도 separable 방식입니다:
- 클릭한 픽셀 기준
radius행에 대해 가로 블러를 계산합니다 - 가로 결과를 세로로 한 번 더 블러합니다
- 전체 이미지가 아닌 최종 1픽셀에 필요한 범위만 역추적합니다
실제 결과, GPU와 CPU 계산이 일치했습니다.
정리하며
- 가우시안 블러는 함수를 커널로 사용하며, 가 블러의 강도를 결정합니다
- 커널 크기는 이 경험적 기준이며, 정규화를 통해 밝기를 보존합니다
- Separable convolution 덕분에 연산을 으로 줄일 수 있고, 이는 가 성립하기 때문입니다
- GPU compute shader에서는
dispatch2번(가로 + 세로)으로 구현하며, workgroup 간 동기화 불가 때문에 배리어가 필수입니다 - 피킹 검증을 통해 GPU 결과와 CPU 수학 계산이 일치함을 확인했습니다
참고 자료
이 게시물은 학습한 내용을 바탕으로 초안을 작성한 뒤, LLM의 도움을 받아 내용을 검수하고 다듬어 완성되었습니다.