TL;DR — 블룸은 threshold, blur, composite 3단계를 compute shader로 처리하는 후처리 기법입니다.
Table of contents
Open Table of contents
들어가며
이전 글에서 가우시안 블러의 수학적 원리와 compute shader 구현을 다뤘습니다. 이번 글에서는 그 블러를 기반으로 블룸(Bloom) 후처리 효과를 구현한 과정을 정리합니다.
블룸은 밝은 부분이 주변으로 번지는 빛번짐 효과입니다. 실제 카메라에서도 발생하는 현상을 후처리로 재현하는 것으로, 게임에서 태양, 폭발, 네온사인 등 밝은 광원 주변의 글로우를 표현할 때 사용됩니다.
이 글에서는 compute shader 기반의 블룸 파이프라인 구조, Vulkan 메모리 배리어와 이미지 레이아웃 전이, 디스크립터 바인딩, 그리고 셰이더 구현까지를 다룹니다. Vulkan의 기본적인 개념(커맨드 버퍼, 스왑체인 등)에 대한 사전 지식이 있으면 읽기 수월합니다.
이 글에서 다루는 내용:
threshold -> blur -> composite3단계 블룸 파이프라인compute shader사이에서 이미지 의존성을 연결하는 배리어 사고방식- 디스크립터 셋,
push constant, 그리고 최종 출력 경로
사전 지식: Vulkan의 커맨드 버퍼, 스왑체인,
compute shader, 이미지 레이아웃 전환 개념을 전제로 합니다.
1. 블룸이란 — 왜 후처리인가
블룸은 3D 오브젝트 렌더링이 끝난 후 이미지 단위로 처리하는 후처리(post-processing) 기법입니다. 씬의 기하 정보가 필요 없고, 최종 렌더링 결과 이미지만 있으면 됩니다. 그래서 graphics pipeline의 버텍스/래스터화 과정 없이, compute shader만으로 구현할 수 있습니다.
3단계 파이프라인으로 구성됩니다:
- Threshold: 밝은 픽셀만 추출
- Blur: 추출한 밝은 부분을 가우시안 블러
- Composite: 원본 + 블러 결과를 합성
2. Compute Shader — fragment로도 되는데 왜 compute인가
Graphics pipeline vs Compute pipeline
Graphics pipeline: 정점 → 버텍스 셰이더 → 래스터화 → 프래그먼트 → 프레임버퍼
→ "삼각형을 그리는" 파이프라인
Compute pipeline: dispatch → 셰이더 병렬 실행 → 끝
→ 렌더링 파이프라인 없이 GPU에서 범용 계산블룸은 fragment shader + fullscreen quad로도 구현 가능합니다. 이번 구현에서 compute를 선택한 이유는 다음과 같습니다:
- 블룸의 각 단계는 “모든 픽셀에 같은 연산 반복”이므로 compute의 dispatch 모델이 직관적입니다
- fullscreen quad는 버텍스 셰이더 + 래스터화를 거쳐야 해서 불필요한 파이프라인 오버헤드가 발생합니다
- compute shader의 workgroup/dispatch 모델을 학습하는 것 자체가 이후 물리/파티클 시뮬레이션의 기반이 됩니다
Workgroup과 Dispatch
GPU는 스레드를 **workgroup 단위(블록)**로 묶어 병렬 실행합니다.
layout(local_size_x = 16, local_size_y = 16) in;
// 1 workgroup = 16×16 = 256 스레드
// 각 스레드가 1픽셀 담당// 800×800 이미지에 대해
vkCmdDispatch(cmd, 50, 50, 1);
// 50×50 = 2,500 workgroup × 256 스레드 = 640,000 스레드올림 나눗셈 (width + localSize - 1) / localSize으로 이미지 전체를 빠짐없이 커버합니다. 이미지 밖으로 나가는 스레드는 셰이더에서 early return 처리합니다.
각 스레드의 동작
ivec2 pos = ivec2(gl_GlobalInvocationID.xy);
// GPU가 workgroup 배치 + invocation 위치를 기반으로 자동 계산
// 이 스레드가 담당하는 픽셀 좌표
vec4 color = imageLoad(inputImage, pos); // storage image에서 읽기
imageStore(outputImage, pos, result); // storage image에 쓰기3. 메모리 배리어 — GPU 내부 교통정리
먼저 구분할 것: dynamic rendering과 compute dispatch는 다른 축
메모리 배리어를 설명하기 전에, 여기서 개념 축이 두 개 섞이기 쉽다는 점부터 정리해야 합니다.
render pass↔dynamic rendering- 둘 다 graphics attachment를 어떻게 다룰지 정하는 방식입니다
draw/blit/dispatch- GPU가 실제로 수행하는 작업 유형입니다
render pass의 반대가 compute dispatch인 것은 아닙니다. compute dispatch는 render pass나 dynamic rendering과 별개의 작업 유형입니다.
메모리 배리어가 필요한 근본 이유도 dynamic rendering 자체가 아니라 작업 사이 리소스 의존성입니다. 한 작업이 이미지를 쓰고, 다음 작업이 그 이미지를 읽거나 다시 쓰면 Vulkan은 그 의존성을 프로그래머가 직접 명시하라고 요구합니다.
다만 graphics 경로에서는 render pass와 dynamic rendering이 차이를 만듭니다.
render pass를 쓰면 attachment의 레이아웃 전환과 일부 의존성을render pass/subpass선언에 포함할 수 있습니다dynamic rendering을 쓰면 그런 정보를 별도render pass객체에 담지 않으므로, attachment 관련 전환과 의존성을 커맨드 기록 시점에 더 직접 관리하게 됩니다
이 프로젝트의 블룸 구현도 두 경로가 함께 있습니다.
threshold -> blur -> composite: compute 경로의storage image의존성blit -> ImGui -> present: graphics 출력 경로의 레이아웃 전환
왜 필요한가
배리어가 필요한 이유는 간단합니다. 한 작업의 결과를 다음 작업이 읽거나 쓸 때, 그 리소스 의존성을 Vulkan이 자동으로 맞춰주지 않기 때문입니다.
이미지는 현재 어떤 용도로 접근할지에 맞는 레이아웃 상태를 가집니다:
GENERAL:compute shader읽기/쓰기TRANSFER_SRC_OPTIMAL/TRANSFER_DST_OPTIMAL: 이미지 복사 소스/대상COLOR_ATTACHMENT_OPTIMAL: 렌더링 대상PRESENT_SRC_KHR: 화면 표시
배리어는 필요에 따라 두 역할을 수행합니다:
- 메모리 의존성/실행 순서 보장 — 이전 작업 결과가 다음 작업에서 올바르게 보이도록 연결
- 레이아웃 전환 — 이미지의 다음 용도에 맞게 레이아웃 상태 변경
중요한 건 “배리어 개수를 외우는 것”이 아니라, 어느 작업이 producer이고 어떤 이미지를 통해 다음 작업이 consumer가 되는지 추적하는 것입니다. 전이 개수는 구현 방식과 blur iteration 수에 따라 달라질 수 있습니다.
스테이지/액세스 마스크
레이아웃 전환과 메모리 의존성이 어느 범위의 작업 사이에서 필요하고, 어떤 접근을 보호해야 하는지를 세부 제어합니다:
- 스테이지 마스크
- 파이프라인 내 어느 단계 범위에 이 의존성을 걸지 지정합니다
srcStageMask: producer 쪽에서 동기화할 작업 범위dstStageMask: consumer 쪽에서 보호할 작업 범위
- 액세스 마스크: GPU 캐시 동기화
- src: 어떤 이전 접근 결과를 다음 단계로 넘길지
- dst: 어떤 이후 접근이 그 결과를 사용하려는지
직관적으로 보면:
srcStage + srcAccess이 조합이 “producer 쪽에서 어떤 결과를 내보내야 하는지”dstStage + dstAccess이 조합이 “consumer 쪽에서 어떤 접근이 그 결과를 기다려야 하는지”
예를 들어 다음 조합은:
VK_PIPELINE_STAGE_2_COMPUTE_SHADER_BIT, VK_ACCESS_2_SHADER_WRITE_BIT,
VK_PIPELINE_STAGE_2_COMPUTE_SHADER_BIT, VK_ACCESS_2_SHADER_READ_BIT이렇게 읽을 수 있습니다:
src:compute shader단계에서 수행한shader writedst: 다음compute shader단계에서 수행할shader read
즉, 앞선 compute shader의 write 결과가 다음 compute shader의 read에서 보이도록 의존성을 거는 것입니다.
GPU 내부에 캐시가 있어서, 스테이지만으로는 부족합니다. Vulkan은 src/dst 접근 범위를 지정해 “이 쓰기 결과를 다음 읽기에서 안전하게 보라”는 의존성을 명시하도록 설계되어 있습니다.
GPU 내부에서는 실제로 어떻게 동작하나
여기서 헷갈리기 쉬운 점은, threshold, blur, composite가 서로 다른 compute pipeline / shader로 실행되더라도 Vulkan에서는 모두 COMPUTE_SHADER 스테이지에 속한다는 점입니다. 즉, stage는 “이 셰이더 파일”을 가리키는 것이 아니라 어떤 종류의 파이프라인 단계인지를 가리킵니다.
커맨드 버퍼에는 보통 이런 순서로 명령이 기록됩니다:
- producer
dispatch barrier- consumer
dispatch
예를 들어 블룸 구현에서는:
horizontal blur dispatchm_brightImage를 읽고m_tempImage에 씁니다
m_tempImage에 대한 배리어src = COMPUTE_SHADER + SHADER_WRITEdst = COMPUTE_SHADER + SHADER_READ
vertical blur dispatchm_tempImage를 읽고m_blurredImage에 씁니다
GPU는 이 기록을 보고, 단순히 “명령 순서대로 한 줄씩” 실행하는 것이 아니라 src에 해당하는 이전 접근 결과가 dst에 해당하는 이후 접근에서 안전하게 보이도록 의존성을 맞춥니다.
m_tempImage 배리어는 다음 의미를 가집니다:
- 이전 compute 작업이
m_tempImage에 쓴 결과를 동기화 범위에 포함하고 - 다음 compute 작업이
m_tempImage를 읽기 전에 - 그 결과가 보이도록 보장합니다
즉, 메모리 배리어는 “어느 셰이더 파일이냐”보다 어떤 리소스에 대해(여기에는 m_tempImage), 이전 compute write 결과를 이후 compute read에서 안전하게 볼 수 있게 만들 것인가를 기준으로 읽는 편이 정확합니다.
여기서 중요한 점은 COMPUTE_SHADER stage 내부에 read 단계, write 단계처럼 공개된 세부 단계가 따로 있는 것은 아니라는 점입니다. compute에서는 각 dispatch가 COMPUTE_SHADER 작업으로 실행되고, 그 안에서 어떤 리소스를 read하고 write하는지가 access mask로 표현됩니다. dispatch 내부의 workgroup 실행 순서는 자유롭지만, dispatch와 dispatch 사이의 해당 접근 의존성은 barrier가 잡아준다고 이해하면 됩니다.
공식 용어: Available과 Visible
Vulkan 스펙과 AMD GPUOpen에서는 이 캐시 동기화를 다음과 같이 표현합니다:
- Making memory available = src 액세스의 flush. “쓴 데이터를 다른 유닛이 볼 수 있게 내보내기”
- Making memory visible = dst 액세스의 invalidate. “읽는 쪽이 최신 데이터를 볼 수 있게 캐시 갱신”
src/dst를 producer/consumer 관계로 이해하면 직관적입니다:
- src (producer): 데이터를 만드는 쪽. “이 스테이지에서 이 접근이 끝나면 데이터를 available하게 해”
- dst (consumer): 데이터를 소비하는 쪽. “이 스테이지가 시작하기 전에 데이터를 visible하게 해”
producer의 write를 consumer의 read/write보다 먼저 보이게 만드는 동기화 계약으로 이해하는 편이 안전합니다.
현재 구현에서 보는 배리어 흐름
threshold dispatch
→ m_brightImage에 write
→ barrier
blur horizontal dispatch
→ m_tempImage에 write
→ barrier
blur vertical dispatch
→ m_blurredImage에 write
→ barrier
composite dispatch블룸 파이프라인의 배리어 — producer/consumer로 읽기
| 배리어 | producer 작업 | consumer 작업 | 대상 이미지 | 레이아웃 | 의미 |
|---|---|---|---|---|---|
| threshold→blur | threshold dispatch | horizontal blur dispatch | m_brightImage | GENERAL -> GENERAL | threshold가 쓴 밝은 픽셀을 horizontal blur가 읽을 수 있게 |
| 가로→세로 | horizontal blur dispatch | vertical blur dispatch | m_tempImage | GENERAL -> GENERAL | 가로 블러 결과를 vertical blur가 읽을 수 있게 |
| 세로→composite | vertical blur dispatch | composite dispatch | m_blurredImage | GENERAL -> GENERAL | 블러 결과를 composite가 읽을 수 있게 |
| composite→blit | composite dispatch | vkCmdBlitImage | outputImage | GENERAL -> TRANSFER_SRC_OPTIMAL | compute 결과를 blit의 source로 사용 |
| blit→ImGui | vkCmdBlitImage | ImGui 렌더링 | swapchainImage | TRANSFER_DST_OPTIMAL -> COLOR_ATTACHMENT_OPTIMAL | blit 결과 위에 ImGui 오버레이 |
| ImGui→present | ImGui 렌더링 | presentation engine | swapchainImage | COLOR_ATTACHMENT_OPTIMAL -> PRESENT_SRC_KHR | 오버레이까지 끝난 스왑체인 이미지를 표시 가능 상태로 |
compute끼리는 레이아웃 전환 없이 캐시 동기화(available/visible)만 수행합니다. 스테이지가 바뀔 때(compute→blit) 레이아웃도 전환됩니다.
GENERAL → GENERAL 배리어가 필요한 이유는, 레이아웃은 같지만 앞선 compute write 결과를 다음 compute read에서 안전하게 보이게 해야 하기 때문입니다.
반복 블러를 켜면 여기에 추가 전이가 더 생깁니다. 현재 구현은 blurredImage → brightImage 복사를 위해 iteration 사이에 GENERAL ↔ TRANSFER_SRC/DST ↔ GENERAL 전이를 넣습니다. 실제 전이 수는 고정 상수가 아니라 파이프라인 구조 + 반복 횟수에 따라 달라집니다.
4. 디스크립터 바인딩 — 셰이더에 리소스 연결
바인딩 흐름
1. 디스크립터 셋 레이아웃: "셰이더가 뭘 쓰는지 정의"
binding 0: STORAGE_IMAGE (입력)
binding 1: STORAGE_IMAGE (출력)
2. 파이프라인 레이아웃: 셋 레이아웃 + push constant → 파이프라인 생성
3. 디스크립터 풀: 디스크립터를 할당받을 공간 확보
풀은 "예산" — 셋을 할당할 때마다 차감
4. 디스크립터 셋 할당 + 이미지 바인딩:
"이 셋의 binding 0 = 이 이미지"
vkUpdateDescriptorSets()로 실제 연결Push Constant — 작은 값 빠르게 전달
디스크립터는 이미지/버퍼 같은 큰 리소스용입니다. , threshold, bloom weight 같은 작은 값은 push constant로 커맨드 한 줄이면 전달할 수 있습니다:
vkCmdPushConstants(cmd, layout, COMPUTE_BIT, 0, sizeof(float), &sigma);디스크립터 셋 생성/할당/바인딩 과정 없이 바로 셰이더에 전달됩니다. 매 프레임 슬라이더 값이 바뀔 때 유용합니다.
블룸에서의 디스크립터 구성
파이프라인 3개:
threshold: 셰이더 + binding 2개 (입력, 출력) + push: threshold
blur: 셰이더 + binding 2개 (입력, 출력) + push: sigma, radius, direction
composite: 셰이더 + binding 3개 (씬, 블러, 출력) + push: bloomWeight
디스크립터 셋 4개 (하나의 풀에서 할당):
thresholdSet: 씬 → 밝은 픽셀
blurHSet: 밝은 → 중간 (가로)
blurVSet: 중간 → 블러 결과 (세로)
compositeSet: 씬 + 블러 → 합성같은 블러 파이프라인을 디스크립터 셋만 바꿔서 가로/세로에 재사용합니다.
5. 블룸 셰이더 구현
threshold.comp
vec4 color = imageLoad(inputImage, pos);
float luminance = 0.2126 * color.r + 0.7152 * color.g + 0.0722 * color.b;
color = (luminance >= threshold) ? color : vec4(0, 0, 0, 1);
imageStore(outputImage, pos, color);휘도(Luminance)는 인간 눈의 색 민감도를 반영한 밝기 값입니다. 초록 > 빨강 > 파랑 순으로 가중치가 적용되며, threshold 미만이면 검정으로 처리합니다.
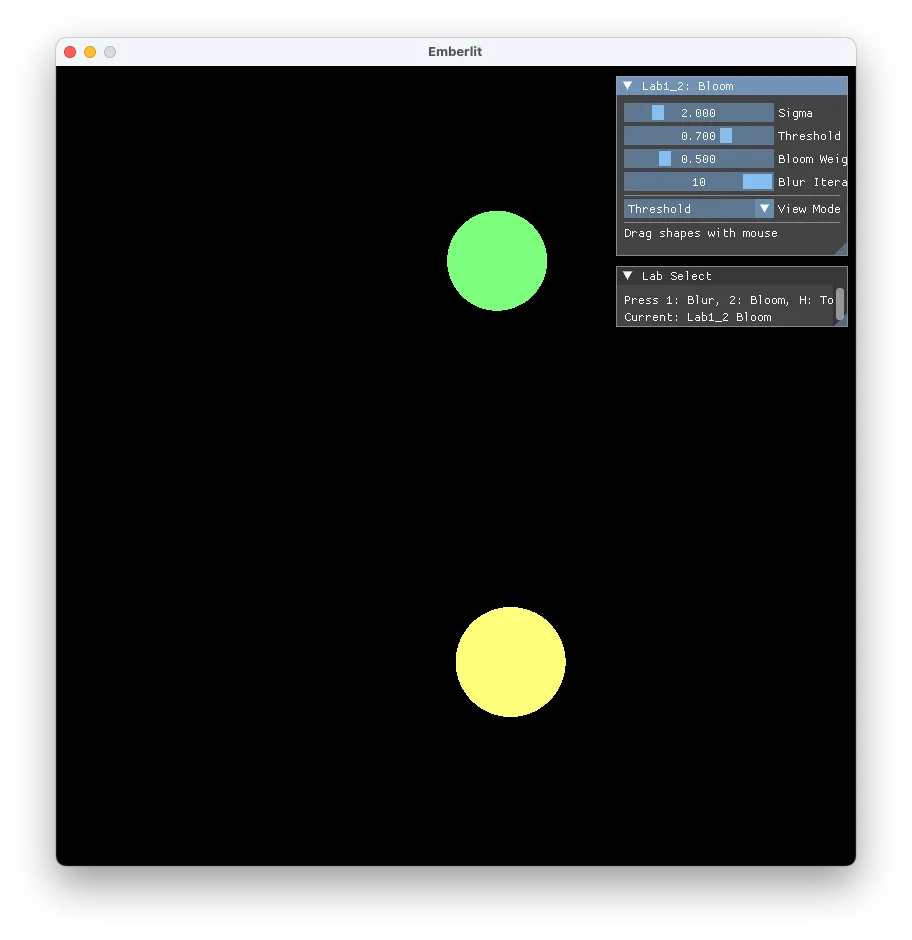
composite.comp
vec4 scene = imageLoad(sceneImage, pos);
vec4 blurred = imageLoad(blurredImage, pos);
vec4 result = clamp(scene + bloomWeight * blurred, vec4(0.0), vec4(1.0));
imageStore(outputImage, pos, result);원본 + 가중치 x 블러 결과를 합산합니다. clamp로 1.0 초과를 방지합니다.
다만 여기서 clamp(0, 1)을 넣은 것은 현재 데모가 rgba8 기반 LDR 이미지이기 때문입니다. HDR 파이프라인이라면 더 높은 정밀도의 렌더 타깃에서 블룸을 합성한 뒤, 마지막 톤매핑 단계에서 표시 범위로 압축하는 쪽이 일반적입니다. “블룸은 원래 clamp해야 한다”가 아니라, 이 구현이 LDR 데모라서 clamp를 선택한 것입니다.
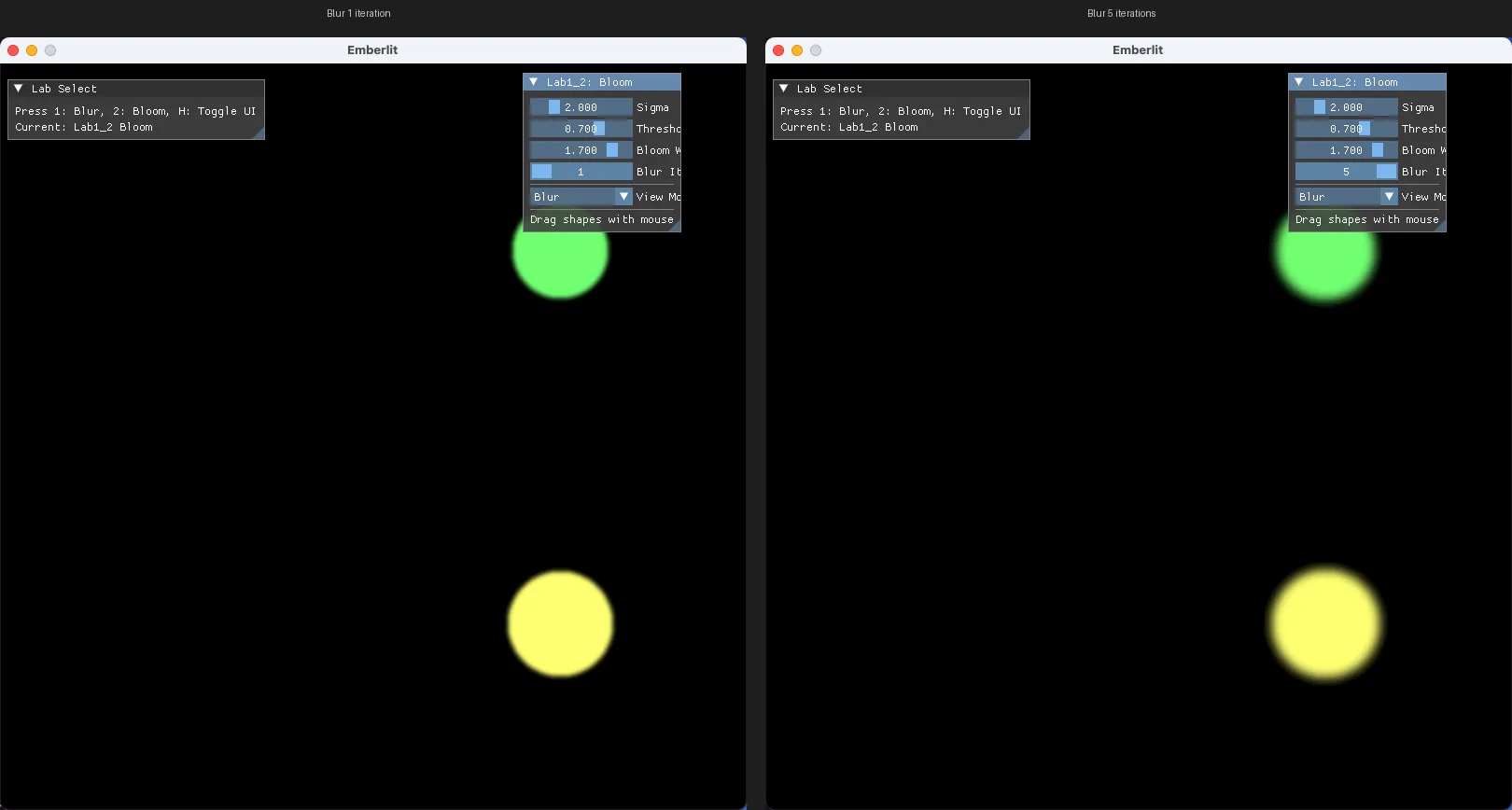
블러 반복
블러를 여러 번 반복하면 더 넓고 부드러운 글로우를 얻을 수 있습니다:
(가로 → 배리어 → 세로 → 배리어) × N회1회 결과를 다시 입력으로 넣어 반복합니다. 반복 시 결과 이미지에서 입력 이미지로 복사(vkCmdCopyImage)가 필요합니다.
6. Compute 결과를 화면에 출력
compute 결과를 화면에 출력하는 다양한 방법이 있습니다. 이 데모에서는 출력 경로를 오프스크린 compute -> blit -> ImGui overlay로 사용했습니다.
Compute shader는 graphics pipeline처럼 자동으로 화면에 “그려지는” 단계가 아닙니다. 현재 구현에서는 오프스크린 storage image에 결과를 쓴 뒤, 그 이미지를 blit으로 스왑체인에 복사해 표시합니다:
compute 결과 (storage image, GENERAL)
→ 배리어: GENERAL → TRANSFER_SRC
→ vkCmdBlitImage → 스왑체인 이미지 (TRANSFER_DST)
→ 배리어: TRANSFER_DST → COLOR_ATTACHMENT (ImGui 오버레이)
→ 배리어: COLOR_ATTACHMENT → PRESENT_SRC (화면 표시)blit은 이미지 간 복사로, 크기 변환도 가능하지만 여기서는 동일 크기 복사에 사용했습니다. 프레젠트는 파이프라인과 무관하며, 스왑체인 이미지가 PRESENT_SRC 상태이기만 하면 graphics든 compute든 상관없습니다.
7. 보기 모드 — 파이프라인 각 단계 확인
ImGui 드롭다운으로 출력 이미지를 전환할 수 있습니다:
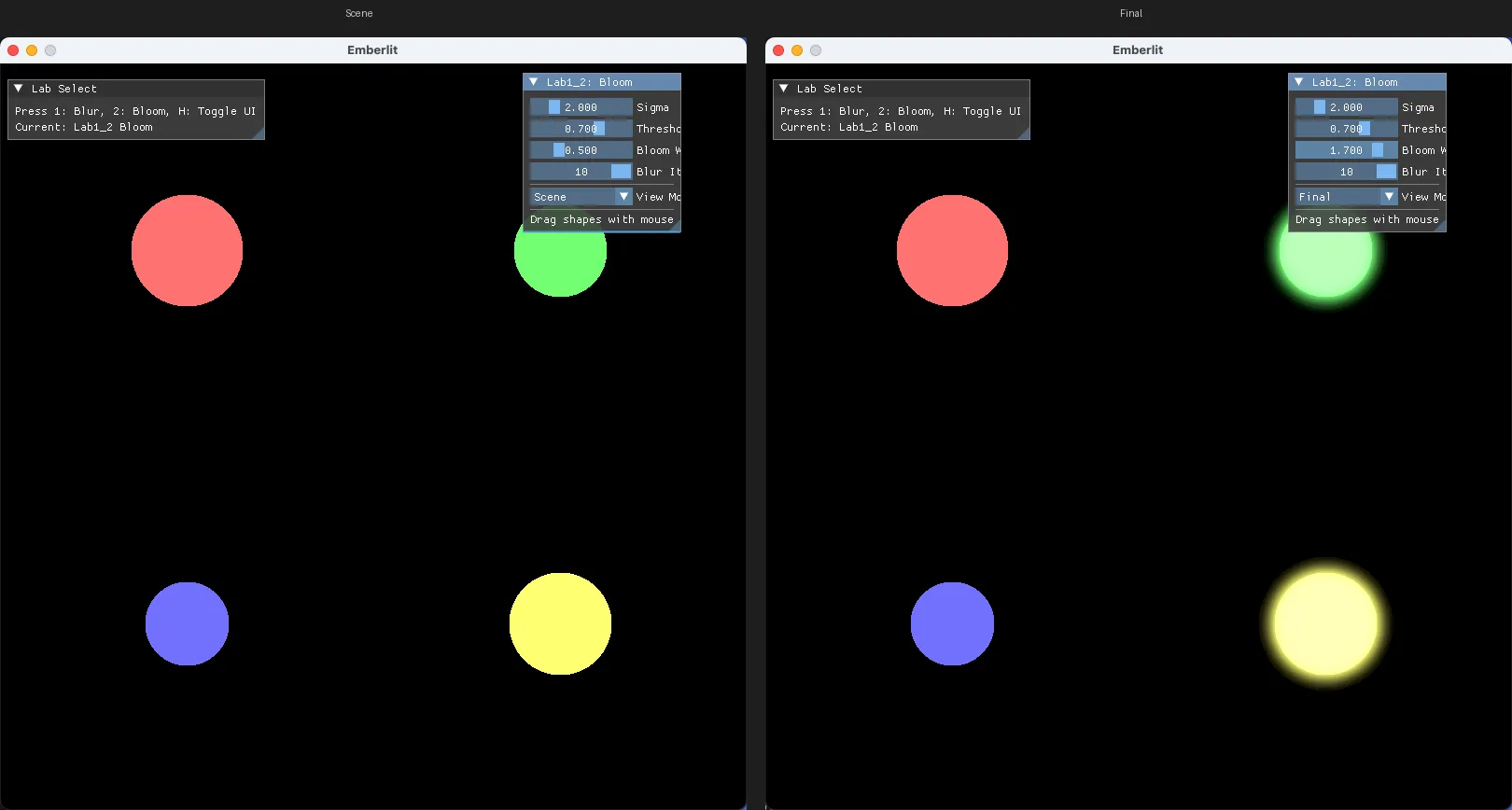
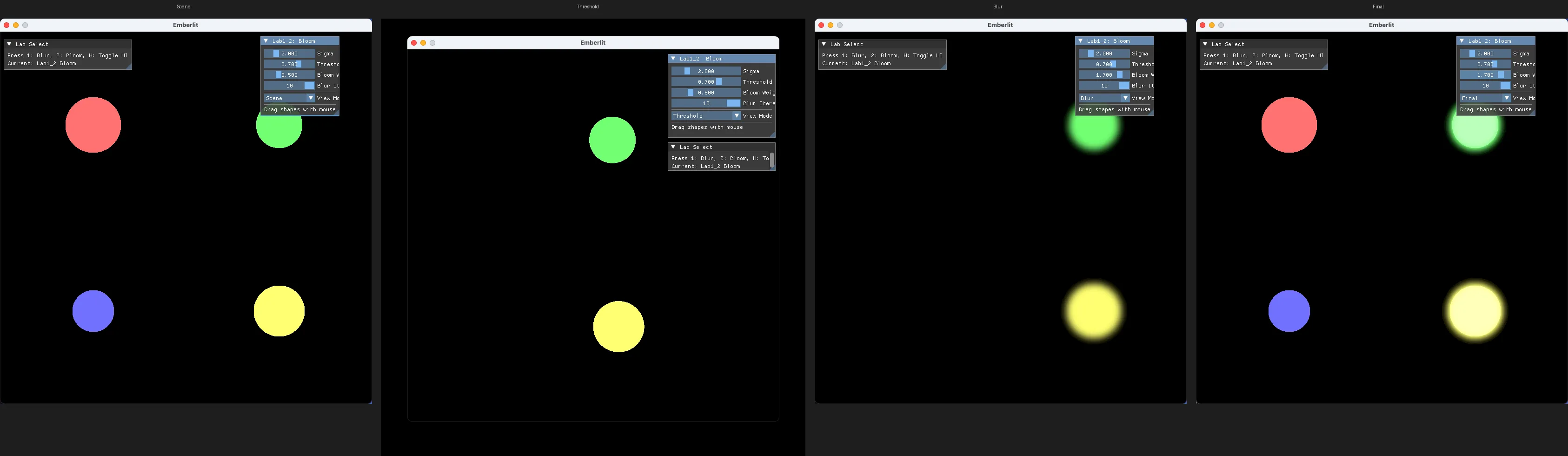
Final: composite 결과 (최종 블룸)
Scene: 원본 씬 (도형만)
Threshold: 밝은 픽셀만 추출된 상태
Blur: threshold + blur 결과 (합성 전)각 단계를 따로 볼 수 있어 디버깅과 학습에 유용합니다. 블룸이 3단계로 이루어진다는 것을 시각적으로 확인할 수 있습니다.
정리하며
- 블룸은 threshold → blur → composite 3단계 후처리 파이프라인으로, compute shader만으로 구현할 수 있습니다
- Vulkan에서는 한 작업의 결과를 다음 작업이 읽거나 쓸 때 배리어로 데이터 의존성을 명시해야 합니다
- 이 예제에서는 compute dispatch 사이의
storage image의존성과 dynamic rendering 기반 출력 경로의 레이아웃 전환을 직접 관리했습니다 - 디스크립터 셋으로 이미지를 셰이더에 바인딩하고, push constant로 작은 파라미터를 전달합니다
- 현재 구현은 LDR 기반 데모이므로 composite에서
clamp를 사용했으며, HDR 파이프라인에서는 톤매핑으로 처리하는 것이 일반적입니다
참고 자료
이 게시물은 학습한 내용을 바탕으로 초안을 작성한 뒤, LLM의 도움을 받아 내용을 검수하고 다듬어 완성되었습니다.